
DataMUXとは?
Transformer系のモデル(例えばBERT等)の推論速度を向上させるアイディアの論文。具体的には、同時に入力できるバッチ数を20倍程度まで増やすことで、通常の1回の推論の時間やメモリリソースで、20回分程度の推論を行う事が出来るようにする。簡単に言うと20倍速にするアイディア
どうやって推論速度を20倍にするのか?
下図の左側が一般的な推論時の処理。NeuralNetと記載のある部分が、例えばBERTなどである。ミニバッチサイズが32の時、32個の文章を一度に処理を行うのが今までの一般的な推論処理である。
本論文の提案手法は、右側の図となる。1,280個の文書を一回のミニバッチとして処理を行っている。1,280=32*40なので、40倍の文章数を一度に処理している事になる。口述するが40倍の量を処理できるが、精度は落ちてくるので、20倍程度までが実用的と思われる。
提案手法はNeuralNetと書かれた部分の左右に、MUX(水色)と、DEMUX(赤色)の部分があるのが構造上の特徴。MUXで圧縮(≒エンコード)して、NeuralNet(≒BERTなど)に入力し、DEMUXで解凍(≒デコード)するイメージとなる。この時、NeuralNetと書かれた白い部分への入力は、左側と同じ32個のミニバッチとなっているので、この部分(例えばBERT)はそのまま使える事になる。
このMUXとDEMUX部分をNeuralNetとつないだ状態で、EndToEndで学習する事で、提案手法が実現する事となる。なお、この学習自体は必要な事であって、特にここは効率化の対象ではない。本提案手法はあくまで推論を20倍などに高速化するのが効果の部分である。

ディープラーニングのお気持ち
さて、なぜこの様な手法で、推論時のミニバッチサイズを20倍などに出来るのか、不思議に思うのではないだろうか。ここからは論文に具体的に書かれてる事はないのだが、あくまで処理のイメージのお気持ちを想像して記載する。
この論文には、ディープラーニングのモデルは十分すぎる次元数など冗長なニューラルネットワーク構造があるので、無駄に重い処理を行っていると主張している。そこで、その冗長な部分を密度高く利用するように出来れば、一度に今以上の多数の推論を行う事が出来るというのがお気持ちの原点である。
例えば、NeuralNetの部分が画像処理だと仮定してお気持ちを考える。通常1枚の画像を入力して、認識結果を推論出力するモデルがあると仮定する。画像の処理する部分を4分割して4枚の画像を一度に処理できるようにすれば、4倍の推論スピードが出せる事になる。ただし、当然、1枚の画像あたりに使えるニューラルネット構造の領域は1/4になる事になる。自然言語のTransformerにおいても同様の事が出来ると考えられる。Transformerの内部は768次元、12のマルチヘッド構造の為、これ全てを1回の推論に使うのではなく、複数に分割して処理が出来れば、画像と同じことが出来る事になる。
このように、ニューラルネットワーク構造の中を複数に分割して使うような、と言っても、実際には、きっちりどこかから分割されるのではなく、学習の過程を通して、上手に最適化されて分割されていくようなお気持ちなのではないかと思われる。この処理を、エンコーダーのMUX、デコーダーのDEMUX、そして、これとEndToEndで結合されたTransformer部全体を学習する事で、最適な分割処理が実現していると考えられる。
MUX部の倍率と、精度の関係
MUX部で何倍に圧縮するかで精度が変わってくる。当然、圧縮倍率を高める程精度が落ちるのが基本的な状況。下図は横軸Nがその圧縮倍率にあたるもの。縦軸が精度で、B1がN=1に相当する原著Transformer。NER(F1)やqqP(Acc.)はN=20とN=40で大きく差があるので、N=20程度が実用範囲かと思われるが、QNLI(Acc.)はなぜかN=40が良くなったりしているものもある。
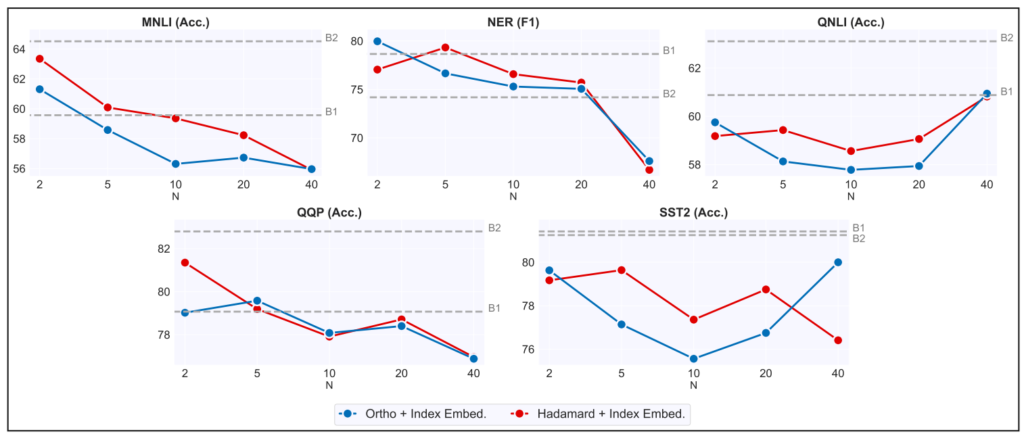
いずれにせよ、B1が元々のTransformer単体の精度なので、N数を高くしても一定の精度が出せている事は驚きでもある。
原著論文
論文タイトル DataMUX: Data Multiplexing for Neural Networks
https://arxiv.org/abs/2202.09318
NeurIPS 2022







