目次
解説する論文
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
既存研究の課題
大規模言語モデル(LLM)は、ChatGPTに代表されるように、自然言語処理において目覚ましい成果を上げています。しかし、既存のオープンソースのモデルは、大規模なインターネットデータで事前学習されているだけで、数学的な推論能力の向上のために最適化されていませんでした。
本研究で解決した課題
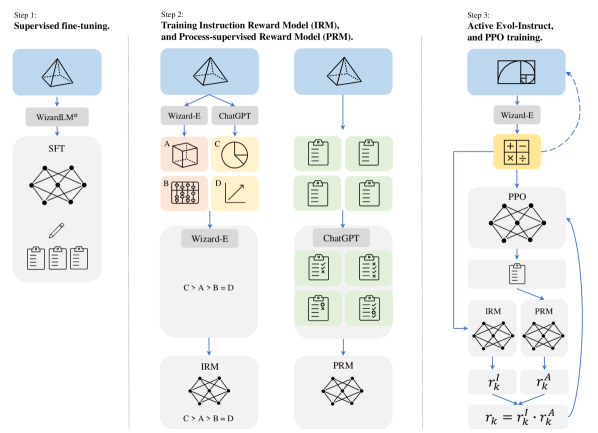
本研究では、RLEIF(Reinforcement Learning from Evol-Instruct Feedback) という新しい手法を提案し、オープンソースのLLMであるLlama-2の数学的推論能力を大幅に向上させました。この手法は、数学に特化したEvol-Instructを用いて多様な数学の指示データを生成し、強化学習と組み合わせることで、モデルが段階的に解答を生成し、その過程を評価・改善できるようにしました。これにより、WizardMathは、既存のオープンソースのLLMだけでなく、ChatGPT-3.5やPaLM-2といったクローズドソースのLLMをも凌駕する性能を達成しました。
有料部分に、論文の全文翻訳サービスがついています
https://note.com/a16mixx/n/ne6298a7d3775
最も参考にした関連研究
この続きはnoteで御覧ください。







