
企画職の為のディープラーニングの論文解説です。DLの概要理解を通してAIのビジネス活用企画を立案する事を目的としておりDL専門家視点での細かな部分の説明は省略していたり、分かりやすく調整している場合があります。
元論文はこちら
要点:強化学習の時系列処理にTransformer(causal transformer)という2021年時点で流行りの高速高性能時系列処理パーツを使ったよ。そうする事で、長い時系列データに対しても良い結果が出たよ。
強化学習とは?
コンピューターが自身で試行錯誤しながらゲームをプレイして上達したり、ロボットを動かして上手に物をつかめるようにしたりする事の手法を強化学習と言います。試行錯誤は基本的には最初はランダムな動きをしながら上手くいった場合を学習していくような事をひたすら繰り返すことで、いつの間にか人間をも超えるまでに学習が進みます。囲碁のチャンピオンを倒した「AlphaGo」も強化学習です。
Transformerとは?
時系列データの処理の手法で、2021年現在流行りの方法(ニューラルネットワークの構造)です。従来は、RNNやLSTMが主流でしたが、Transformerが考案されてからは、圧倒的に性能が良く、スピードも速いため、Transformerが重宝されています。
時系列データとは、例えば文章は時系列データです。「首都高で綺麗な景色を見ながらドライブする」という文章は、「首」の文字の次に「都」がきて、「高」が続きます。このようにデータが時系列に並んでいます。インターネットのアクセスログをディープラーニングで処理する際も時系列データとして処理できます。何にアクセスして、次にどこにアクセスし、その次に何をしたか、という時系列データです。
この論文ではどうやって検証しているのか?
いくつかのゲームのプレイなどをTransformerベースの強化学習を行って、そのゲームのスコアなどを従来方式と競っています。
具体的には、ATARIのBreakOutなど、OpenAIGymのHalfCheetahなど、Key-To-Doorタスクをプレイさせています。
当論文、Decision Transformerのミソは?
下図の、ディープニューラルネット構造がミソです。図中で、Transformerは真ん中の「causal transformer」と書かれている部分です。
入力は、下部のR,s,aの3つがセットで、1つの時系列データになります。よって、この図は2つの系列データを処理している例になります。文字でいうと最初の2文字という事になります。実際には、この系列の「長さ」をいくつにするかは事前に決めておきます。2でも良いし、128でも、1,024でもOKです。
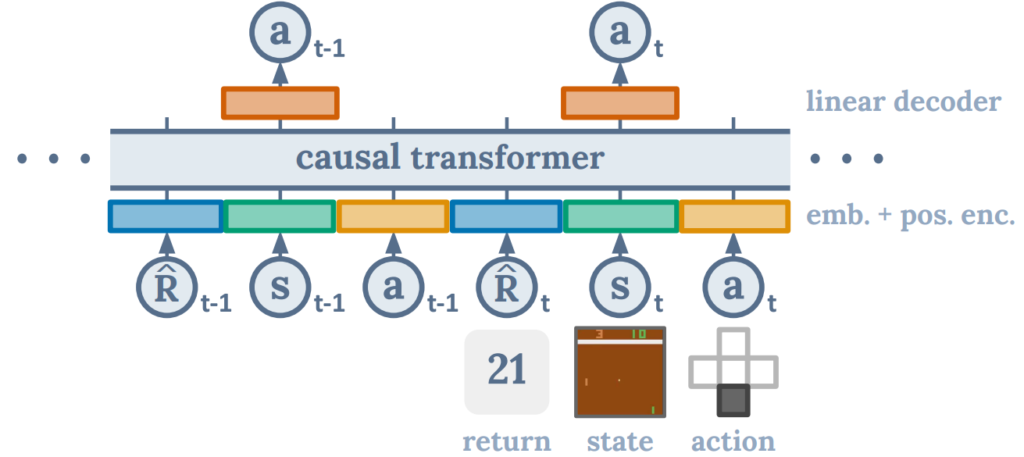
入力側は、Rはスコア、sが状態(すなわちゲームであれば画面の画像データ)、aがアクション(すなわちゲームであればコントローラーのどのボタンを押したか)の組み合わせが、時間順にずらっと並ぶ。1秒間に30回画面が更新されるのであれば、1秒間で30系列のデータとなる。出力側(正解データ側)はa(アクション)の時系列データである。すなわちゲームに関わる全情報を入力し、コントローラーの操作の関係をTransformerに学習させる訳である。
causal transformerとは?
上図の中心に書かれているcausal transformerとは何だろうか?transformerは時系列の入力と出力の関係性を学習するニューラルネットワークの構造である。WOLFRAMのサイトの図が分かりやすい。
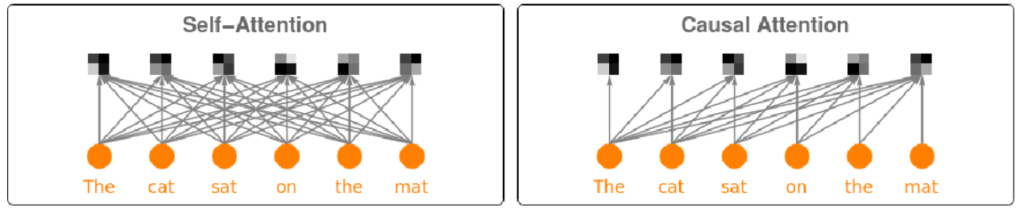
左側が一般的なBERTの構造で(実際の構造はもっと複雑なので模式図と思ってほしい)各時系列の入力と出力がすべてつながっている。対してcausal transformerやGPTの構造は右側であり、時系列の過去の時点が未来の全ての時点には関係しているが、逆のつながりはない。よって、ゲームのように過去の状態からしか未来の状態が変化しないものはこの構造を使うのが望ましいという事になる。逆に、文章のように、末尾の情報が先頭の情報にも影響するような、例えば「首都高速は好き、ではない」のように最後の否定語が文章全体の意味に関わるようなものは、左側のself-attentionの構造が望ましい。
結果は?
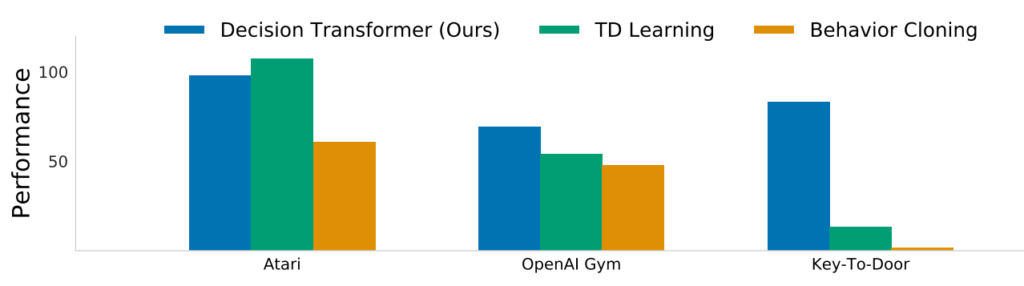
Atariのゲームや、OpenAI Gymのタスク、Key-To-Doorのタスクによる、従来手法(緑とオレンジ)と、当手法(青)のパフォーマンスの結果(高い方が良い)。Atariのゲームでは従来手法の方が良い結果が出ているが、特にKey-To-Doorのタスクにおいては当手法が圧倒的に良い結果を出している。

プレイヤーはベージュのピクセで,鍵は茶色で,リンゴは緑で,最後のドアは青で表されています。
エージェントは,白で示された部分的な視野しか持っていません。
Key-To-Doorタスクというのは、3つの面(部屋)があり、プレイヤーは、最初の部屋で鍵を拾わなければなりませんが(これがないと最後の部屋でGOALできない)すぐには報酬を得られません。2番目の部屋では,エージェントは10個のリンゴを拾うことができ,それぞれすぐに報酬を得ることができます。最後の部屋では,エージェントはドアを開けることができ(最初の部屋で鍵を拾った場合のみ),わずかな報酬を得ることができます。という風にかなり長い依存関係を学習する必要があります。
まとめ
強化学習で、長い時間軸での依存関係(報酬関係)を正しくとらえたい場合は、当論文の手法を使う事で2021年時点で最高の性能を得られそう。




