
文系企画職の為のディープラーニングの論文解説です。DLの概要理解を通してAIのビジネス活用企画を立案する事を目的としておりDL専門家視点での細かな部分の説明は省略していたり、分かりやすく調整している場合があります。
元論文はこちら(2021年2月の投稿論文)
要点:Transformerの構造は全体のニューラルネットワーク接続が密結合になっている為、これを細かなモジュール単位に分解して疎結合にする事で、処理速度の向上や、性能の向上につながるのではないか?というアイディアを実際に試して、精度を計測した論文。
TIMの構造とは?
本論文で提案しているTransformers with Competitive Ensembles of Independent Mechanisms(=TIM)の構造は次のようである。「東京一極集中が加速」という文章を下から入力しているイメージを図にしている。文章は単語のような単位に分解されて入力するのが一般的。ここの詳細はBERT等の論文を参照。もちろん、文字単位で入力する事も可能であるが、その場合は系列長が長くなるので、処理に時間がかかるようになる。この図でいうと系列長は6である。6単語、もしくは6文字を処理できる構造である。
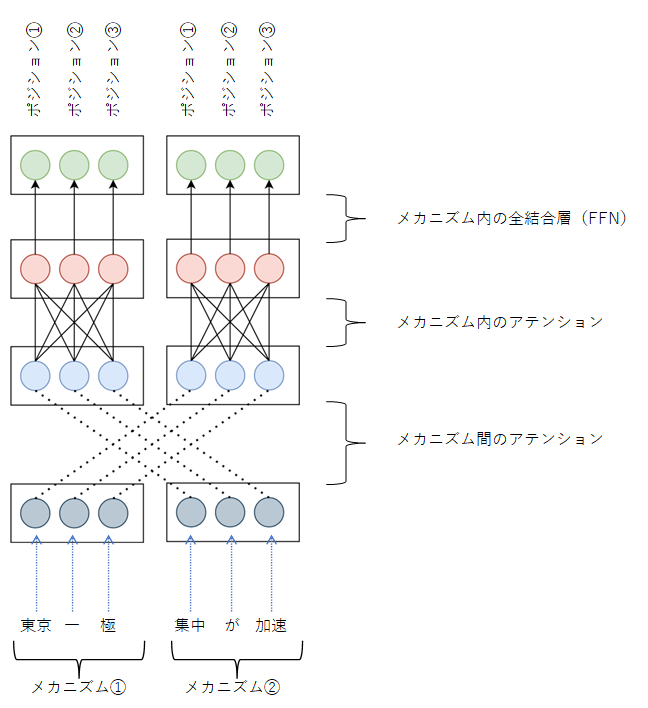
この図で「アテンション」とは、どこの情報を重視するかの重みづけを行う(学習する)イメージの構造の事。下の点線がクロスしている部分で言うと、どこのメカニズムの情報が重要かが重みづけしてデータが伝わっていくイメージ。これに対して、FFNはフィードフォワードネットワークと言われ、それぞれ各層のニューロンが一つ前の層と次の層の全てのニューロンが接続されている、最も基本的なニューラルネットワークの構造の事。
TIMのミソは、メカニズムという単位にモジュール化されている事。この図の場合、「東京 一 極」の部分がひと塊のメカニズムとしてモジュール化されており、次の「集中 が 加速」の3つでまたひとつのモジュールの塊となっている。このように、モジュールに分割して疎結合にする事で、性能向上や処理速度向上、汎化性能の向上などが期待できるのでは?というモチベーションに基づいた研究である。
Transformer(BERT)の構造は?
TIMが比較対象としている、Transformer構造をベースとしたBERTの構造は下図のようである。
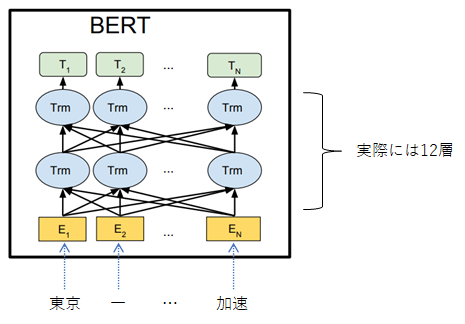
図のように、文章の開始から終了まで(E1~EN)全てが、TIMでいう1つのメカニズムとなっており、系列長であるNが長くなると、上図の相互に結合している矢印(密結合)(アテンション構造)がかなり多くなることが想像できると思う。このようにモデル全体が密結合なものに対して、TIMはメカニズム単位でモジュール化して、疎結合な状態の構造としている。
性能はどうか?
音声データのノイズ除去
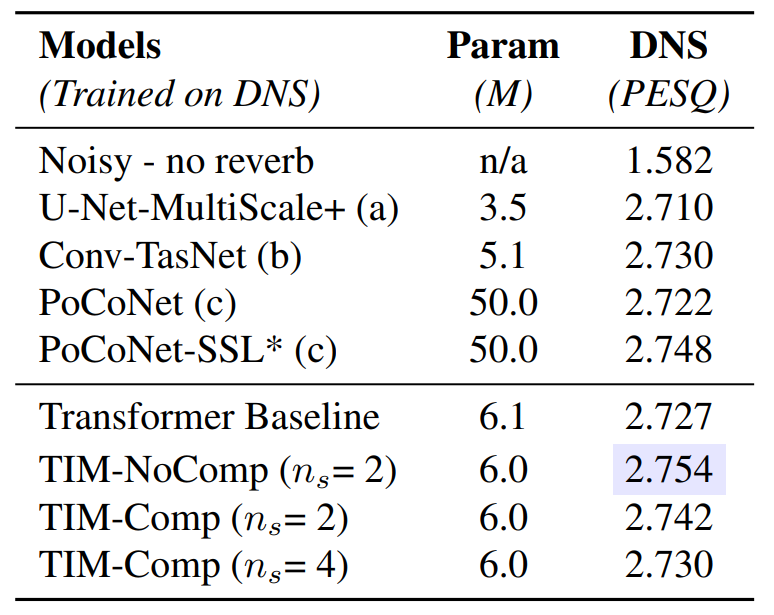
TIMと書かれている部分が本論文の成果。DNSのところの数値が高い方が性能が良い。よって、最も良い性能が得られたとのこと。
文章の理解
BERTの中身をTIMに置き換えると性能が良くなるという結果となっています。BERTの全部の層をTIMに置き換えると性能は下がってしまうようで、最初の2層と、最後の層はBERTのまま、その他の中間層をTIMに置き換えています。
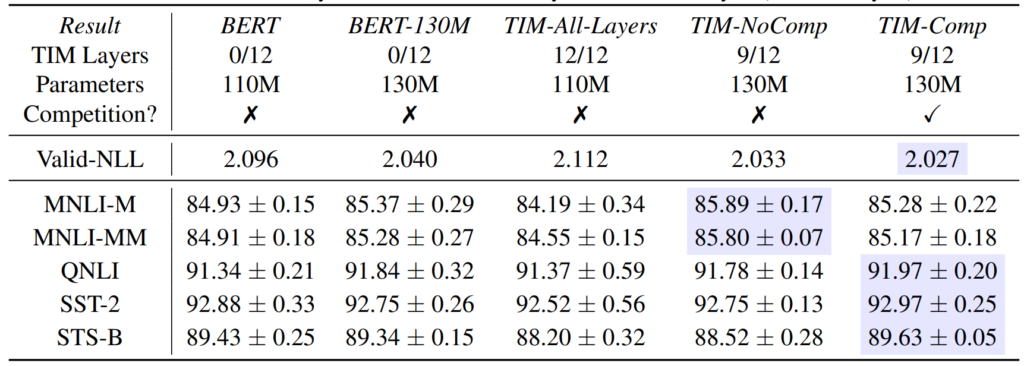
票のように、網掛け部分が最も良い性能を出しています。MNLI-MやMNLI-MMというテストでは、TIM-NoCompの12層中9層をTIMに置き換えたものが最高の成績。QNLI以下はTIM-Compの同じく12層中9層をTIMに置き換えたものが最高の結果を出しています。
まとめ
BERTのような密結合なモデル構造に対して、TIMというモジュール単位で疎結合な構造を試してみた。
結果はタスクによっては最高の精度をだしているが、ずば抜けて高い性能をたたき出したわけではない。
ただし、モジュール化(疎結合)という考え方は、特定のタスクで高い性能を出す可能性や、処理速度等でアドバンテージが出る可能性もあり、今後の発展に期待したいところ。




