
文系企画職の為のディープラーニングの論文解説です。DLの概要理解を通してAIのビジネス活用企画を立案する事を目的としておりDL専門家視点での細かな部分の説明は省略していたり、分かりやすく調整している場合があります。
元論文はこちら(2021年8月投稿)
要点:文字で指示を与える事で、画像を変換するよ。例えば、普通の車の写真をスポーツカーの写真に変えたり、顔の写真をスケッチ風などに変換したり、ディズニー風にしたり、どんな変換でも文字での指示のみで変換可能。この論文のポイントはその際に、ドメイン外の領域にも文字の指示だけで変換できること。ドメイン外とは、学習した元画像データ群に含まれない領域の事。例えば顔写真しかないのに、写真ではない手描きスケッチ風に変換できる。
StyleGAN-NADAによる画像変換の実例
実際にどういう事が出来るのか、筆者がやってみたので、画像変換の実例結果を示す。なお、上記にリンクのある元論文にも変換事例は複数掲載されているが、より面白そうなものを試してみた。
車写真のスポーツカー変換
変換指示文字列
Family Car → Sports Car
変換前

変換後(スポーツカー)

デザイナーのスケッチ画像変換
変換指示文字列
photo → art design sketch
変換前

変換後(デザイナーのスケッチ画像)

顔写真のギャル変換
変換指示文字列
face → gyaru
変換前

変換後(ギャル)

顔写真の女性経営者変換
変換指示文字列
face → women business owner
変換前

変換後(女性経営者)

入力と出力の整理
何を入力として、何を出力する論文なのかを整理する。
入力
- 元画像のStyleGANによる学習済みモデル。
元画像群は、顔(FFHQ)、猫、犬、教会、車、馬の各写真画像で行っている。
StyleGANの学習にはかなりの時間を要するが、本論文ではその学習済モデルを用いている為、ここの学習に時間はかからない。
この元画像群の外に変換できる事が当論文のミソ - 画像と文字のペアの学習済みモデル。
StyleCLIP: Text-Driven Manipulation of StyleGAN Imageryという論文のデータ。WEBから収集した4億組の画像とテキストのペアを学習させたもの。これを用いる事で文字ベースで画像をドメインごと変換する。 - 変換を指示する文字。sourceとtagetの2つの文字を入力する。
出力
変換前後の画像を出力する。変換前の画像はランダムなzからランダムに決められる。
特徴
当論文では画像は学習済みモデルを活用しており、文字での変換指示を与えるだけの為、変換自体は非常に高速(数分)で出来る。(GPU環境)
仕組み
StyleGAN
本論文のミソとなるパーツの一つ目は、StyleGAN(A Style-Based Generator Architecture for Generative Adversarial Networks)(2018年12月の論文)です。StyleGANは簡単にいうと、2021年時点でおよそ最も高解像度の画像を生成するGANの仕組みです。これの使い方を非常にシンプルに理解するには下の図を見てください。StyleGANは既に学習済みとします。

zベクトルを入力に与えると、画像を生成します。基本的にはそれだけです。ここでzベクトルとは何でしょうか?とても簡単に理解するには、下記の図のようなものです。
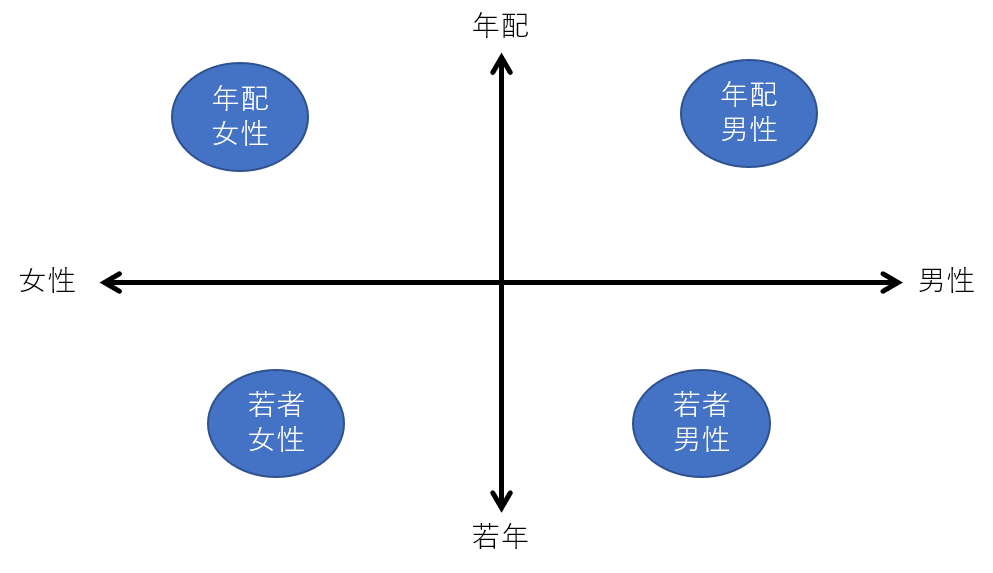
ベクトルですから、2次元ベクトルだとすると、この図のようにx軸とy軸の2つの軸で表すことが出来ます。例えば横軸が性別、縦軸が年齢だとします。右上の象限、すなわち、xもyもプラスだと年配男性を表すとします。yが上に行けば行くほど年齢が上がることになります。右に行けば行くほど、より男性らしいという事になります。2次元のベクトルだとすると、zはxとyの値を入力する事になります。ある画像を生成して、もう少し若くしたいと思えばyの数値を小さくすればそういう画像が出てくることになります。
実際のzベクトルは数十~数百次元を取ります。また各次元が男性女性とかに割り当てられているわけではなく、ディープラーニングが勝手にその次元空間内に意味合いを割り付けていきます。しかも、ある程度湾曲していますので、人間が理解出来るような整理された状態ではありません。
StyleCLIP
web上から画像とテキストのペアを大量に学習したものです。これを使う事で、先の例のように、”Family Car”のベクトルの場所と、”Sports Car”のベクトルの場所が分かります。即ち、 “Family Car” から”Sports Car”に変換するには、どちら方向にどれだけベクトルを動かせばよいかが分かります。頭の中の理解は上図のように2次元で十分です。上のベクトルの説明図を見ると、年配男性を若年男性に変換したい場合は、y軸方法に数値を減少させれば良いことが分かります。これが実際のプログラムの中では百次元などのレベルで自動的に行われます。
StyleGAN-NADA
本論文のミソの構造は次の図のものです。Gは生成器です。GfrozenとGtrainがあります。Wは学習済モデルの数値で、初期時点ではGfrozenもGtrainも同じものが入っています。即ち、最初は両方とも左からzベクトルを入力すれば同じ画像を生成します。
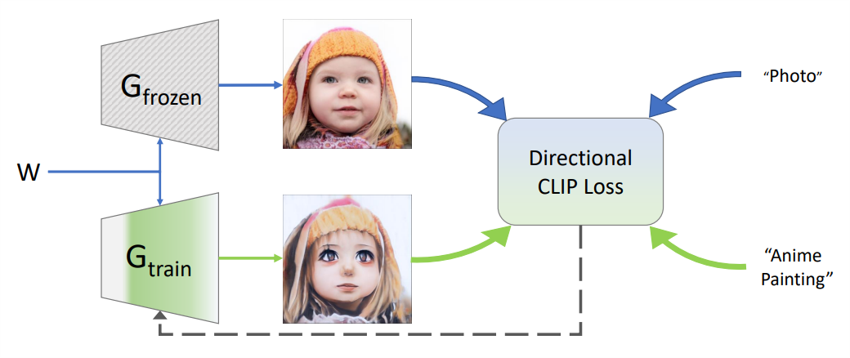
ここから、学習を進めます。変換指示は、この図では”Photo”から”Anime Painting”に変換しろとなります。Gfrozenはfrozenと名の通り、学習しません。固定したままです。Gtrainの方を学習させ、中身が学習に応じて変化していきます。まず、Gが2つ存在しているというのが、この論文のミソの一つ目です。次にミソの2つ目は”Directional CLIP Loss”の部分です。これは先に述べたように、 “Photo”から”Anime Painting”に変換するには、ベクトルをどの方向に動かすのかという事を行います。先の若年男性の簡単な例でいうとy軸方向を減らすという事でしたが、それと同じような事をやります。Gfrozenという固定した生成器から出てきた画像に対して、 ”Anime Painting” 方向にずらした部分を「正解」とします。
より具体的に理解する為に筆者の作成した図を下に示します。

学習させる部分は(*)部分なのですが、何を正解として学習させるかというと、face→gyaruの変換の場合、StyleCLIPによるベクトルの変換方向を出しこれを正解の方向とし、現在のStyleGANから生成される画像をStyleCLIPに入力して出てくるStyleCLIP上のベクトルの位置関係を先の正解の方向に少し動かすようにという正解を逆伝搬させ、(*)部分を学習(修正)する事でそれに近づけるように修正を繰り返して(=学習)していきます。その他細かいことを色々論文ではやっていますが、大筋はこのような事を行っています。
まとめ
当論文のミソをまとめます
- 文字で指示をする事で、元画像を変換した新たな画像を生成します。
- 従来の画像生成では、画像生成器であるGANが学習したドメインの中(写真なら写真の範疇のみ)での変換しか出来ませんでしたが、当論文ではドメイン外の画像に変換できます。
- StyleGANという画像生成器と、StyleCLIPというWEB上の画像とテキストのペアというドメイン多様性のあるデータを組み合わせる事でこれを実現しています。
- 当論文では、StyleGANとStyleCLIPの学習済みモデルを活用している為、変換処理は高速で数分で処理が完了します。




