論文の基本情報
- META社(旧facebook)AI研究所の論文
- 2022年1月発表
- 元論文(https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language/)
何が出来るの?
画像、言語、音声などのデータを、正解データ「なし」でデータ自体を大量に与えるだけの方法で学習する事で、それらのデータの意味合いをベクトルに変換する方法を表現学習と言い、その手法の論文です。例えば、車の画像と、別の車の画像は、いずれも車の画像ですので、それぞれの画像はベクトル空間上の近しい点になります。対して、車の画像と、人間の顔の画像は、意味合い的に近くないため、それぞれの画像はベクトル空間上の遠い位置の点となります。
従来手法と何が違うの?
表現学習で、画像、言語、音声それぞれのデータは、それぞれのデータに適したディープラーニングのモデル構造を用いて学習する必要がありましたが、本論文では骨格の部分について全く同一の構造を用いて、これら全てのデータ形式を表現学習する事が出来るようになりました。
性能はどうなのか?
学習の精度についても、従来の手法(画像、言語、音声にそれぞれ適した方法)に比べておよそNo.1の性能を出すことが出来ています。
画像、言語、音声、全てに使える同一の構造って何がうれしいの?
骨格部分が同一構造であれば、入力データが画像、言語、音声など、様々な形式であっても、骨格部分で同じ意味合いとして統合して処理できる可能性があります。例えば、車の「画像」と、車という「言語」、車としゃべっている「音声」を、骨格部分では同じ「車」として認識し、処理することが出来ると思われます。
従来のそれぞれ別の構造のモデルであれば、車の画像から表現学習した「ベクトル」と、車という言語から表現学習した「ベクトル」は別のものとなります。これらを統合していく手法もありますが、その手間などが省けると考えられます。
上記は論文に書かれているメリットではありませんが、論文中での主張としては、人間が視覚的な理解をする場合と、言語の理解の場合、同じような学習プロセスを脳内で行っているので、ディープラーニングでもそのようなモデル構造でうまくいくはずであり、その方が性能も良いはずである、との主張がなされています。
どんな手法で実現しているの?
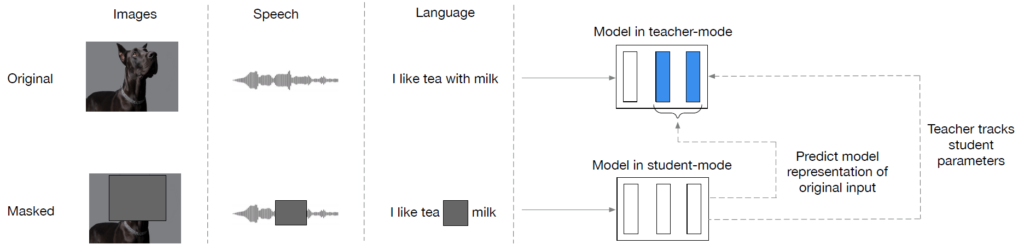
図のように、ディープラーニングのモデル構造は、教師モデルと生徒モデルの2つがある。青色のが教師モデル。その下の縦の長方形が3つ並んだ白黒の図が生徒モデル。画像や音声、言語のデータを、教師モデルにはそのまま全部を入力する。生徒モデルには、図のように一部をマスクしたものを入力する。画像の場合は一部が黒塗りされていたり、音声の場合は音が一部消えていたり、言語の場合は単語が抜けているという事である。
次に、教師と生徒それぞれのモデルの出力を比較し、生徒モデルを教師の出力に近づけるように(生徒だけを)学習する。学習するとは、モデル内のパラメータを(出力が教師に近づくように)更新する事である。生徒モデルを教師モデルの出力を正解として学習するので、一般的な蒸留という考え方に即したものである。そして、次が特徴的な方法だが、教師モデルは、生徒モデルの各パラメータと教師モデルの各パラメータの重みづけ平均をとり、それを教師モデルのパラメータとして更新する。この手法をEMA(exponential moving average)と言う。重みづけ平均の部分を数式で見ると次の通り
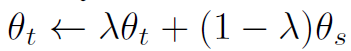
λの値は0.996から1.0までcosスケジュールで変化させると書かれているので、生徒のパラメータのθsに掛けられる係数はかなり小さな値という事になる。即ち、教師のパラメータθtに大部分の重みをかけ、生徒のパラメータをほんの少し取り込むという理解で良いかと思う。なお、この手法を正解データなし(ラベル無し)の自己蒸留の手法と呼ぶ。
これを多数のデータで学習する事で、教師モデルが出来上がっていくこととなる。
教師や生徒モデルの具体的な構造は?
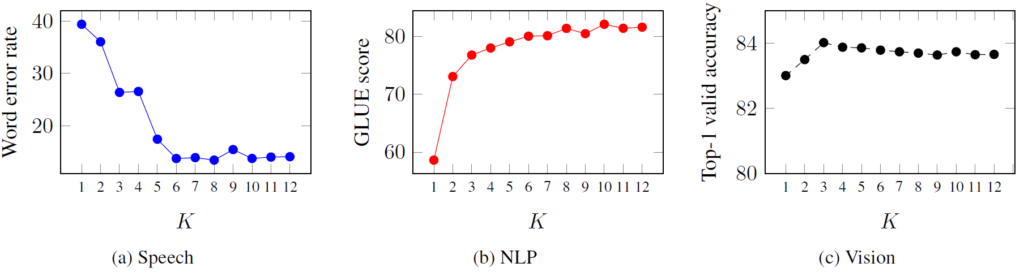
標準的なTransformer構造を用いています。ただし、一般的なTransformerは複数の層が重なっている「最後の層」の出力「のみ」を出力として用いるのに対して、本論文の手法では、「最後からN層」分の出力を平均したものを出力として用いているという特徴がある。Nをいくつにすると性能が良いかについては下記のようになっている。