
企画職の為のディープラーニングの論文解説です。DLの概要理解を通してAIのビジネス活用企画を立案する事を目的としておりDL専門家視点での細かな部分の説明は省略していたり、分かりやすく調整している場合があります。
元論文はこちら
要点:ディープラーニングのここで言う「ドメイン」というのは、例えばイラストの飛行機と、写真の飛行機の違いの事。イラストドメインと、写真ドメインという事。「ドメイン汎化」とは、イラストだろうが写真だろうが、飛行機を飛行機と認識する汎化の事。2021年現在、ドメイン汎化は多くの研究があるが、それらを再現し公平に比較できるようになっていないので、それが出来るように色々整備したよ、という論文。
ディープラーニングで言う「ドメイン」とは?
ディープラーニングのここで言う「ドメイン」というのは、例えばイラストの飛行機と、写真の飛行機の違いの事。飛行機の具体例は下図の最下段のDomainNetと書かれている行の各画像データ。これは全て飛行機であるが、手描きだったり、写真、イラストだったりする。これら各ドメインの飛行機の画像を、正しく飛行機と認識したいという事。
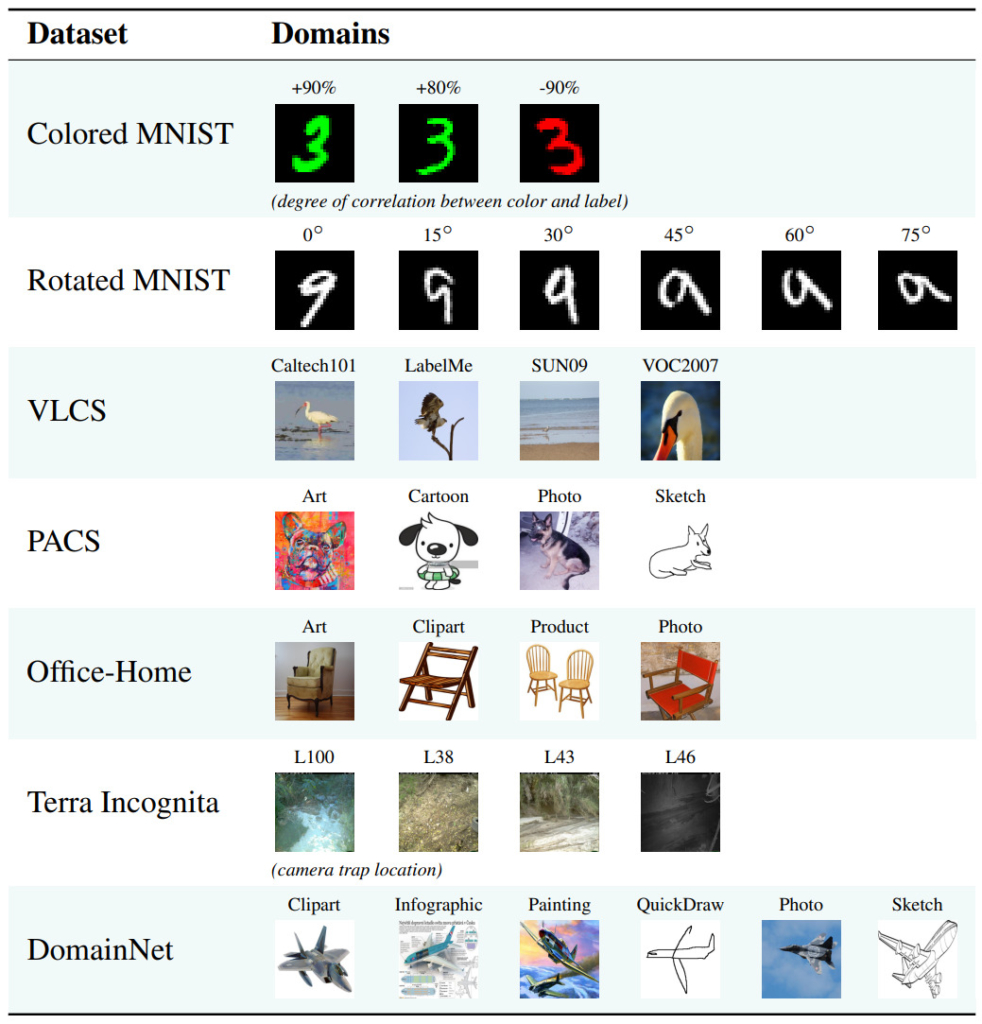
図1
ディープラーニングのドメイン汎化問題とは?
ディープラーニングおよび機械学習システムでは、AIが学習時に使ったデータの分布の中に対してはうまく動作するが、分布外のデータに対してはおかしな挙動を起こすことが多い。分布というのは、分かりやすく言うと先の飛行機の例のように、実際の飛行機の写真画像の集合と、線画で描いてある飛行機の画像の集合は分布が違うという事である。また、同じ写真画像であっても、カメラが違う機材であったり、レンズが違うなどでも分布はある程度違うという事になる。よって同じ写真画像であっても正しく判定できる程度の分布の違いの場合もあれば、正しく判定できない大きな分布の違いの場合もある。
例えば、自動運転システムにカメラによる画像認識を使おうとした場合、光の変化や、天候、物体の姿勢など、AIが学習した時の画像と分布が異なれば、AIの性能パフォーマンスは低下する事となる。医療システムの場合は、ある病院で収集された画像で学習したAIは、他の病院の別の医療器でも正しく使えるとは限らない。
ドメイン汎化とドメイン適応の違い
ドメイン汎化(Domain Generalization)と、ドメイン適応(Domain Adaptation)の違いは、一言でいうと、実際に使うデータが学習時にあるかどうかの違い。
ドメイン汎化は、実際に使うデータが「ない」状態で学習して、未知のデータで実際の処理を行う。例えば、写真の飛行機だけで学習して、実際の本番でイラストの飛行機を判定できるかという問題設定。
ドメイン適応は、実際に使うデータが「ある」状態で学習する。具体的には、実際に使うデータが「ない」状態の画像の学習済みモデルが既にある状態で、その学習済みモデルに対して、実際に使うデータで転移学習を行う。BERT的に言うとファインチューニング学習を行う。一般的には、膨大なデータで事前学習した学習済みモデルに対して、少量の実際に使うデータでさらに学習をする事で、その実際に使うデータのドメインの特徴を学習する。
各手法によるドメイン汎化性能を公平に比較できるプラットフォームを作ったよ
当論文のメインテーマのひとつはこれ。下記のgithubにそのプラットフォームを作ったので、皆さん使ってねという事。ここに新たなモデルを投入して、同じデータ、同じ条件で、その性能を比較できるようにしようという事。
https://github.com/facebookresearch/DomainBed
主なドメイン汎化手法
上記のプラットフォームでは、同一のデータセットを用いて、違う手法で性能を比較する。論文内に記載されている下記の手法は最もベーシックな汎化の手法一覧と考えられる。
- Empirical Risk Minimization (ERM, Vapnik, 1998)
ドメイン間の誤差の合計を最小化するように学習する - Group Distributionally Robust Optimization (GroupDRO, Sagawa et al., 2020)
誤差が大きいドメインの重要性を高めながらERMを行う - Interdomain Mixup (Mixup, Yan et al., 2020)
同一ラベルのランダムな画像(各ドメイン)間の線形補間でERMを実行 - Meta Learning Domain Generalization (MLDG, Li et al., 2017)
ドメインを超えて一般化する方法をメタ学習する - ドメイン間で一致する分布を持つ特徴量を学習する人気のアルゴリズム
- Domain Adversarial Neural Network (DANN, Ganin et al., 2015)
特徴量の分布を一致させるために敵対的ネットワークを用いている - Conditional Domain Adversarial Neural Network (C-DANN, Li et al., 2018)
ドメイン間の条件付き分布をマッチングする - Deep CORAL (CORAL, Sun and Saenko, 2016)
特徴量の分布の平均と共分散を照合 - Maximum Mean Discrepancy (MMD, Li et al., 2018)
特徴分布のMMDを一致させる
- Domain Adversarial Neural Network (DANN, Ganin et al., 2015)
- Invariant Risk Minimization (IRM, Arjovsky et al., 2019)
特徴表現を、複数のドメイン間で適切に分類する線形分類器を学習する
結果
当論文の著者達が実装したERMのモデル(下図 Our ERM)が最高の性能を示した。
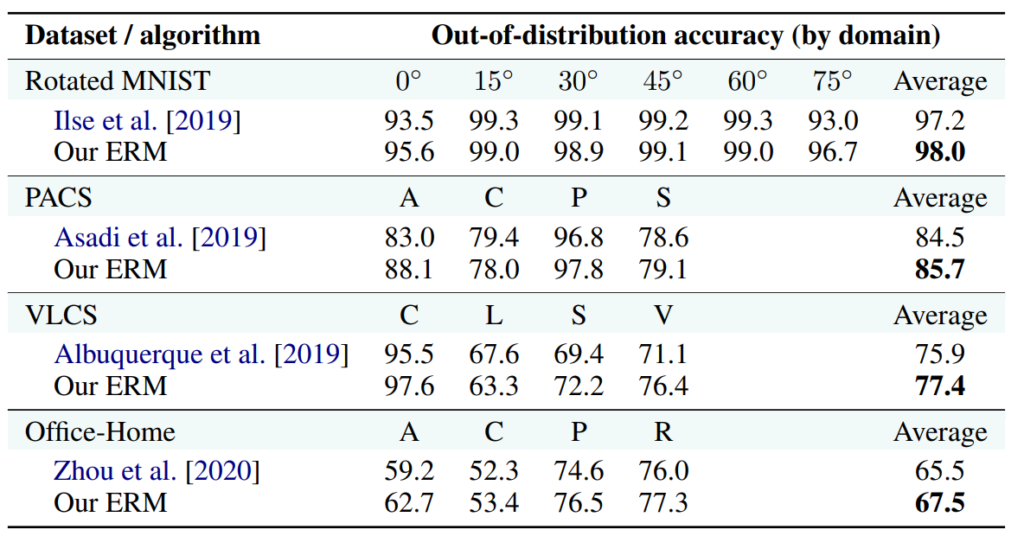
すべての条件が同じであれば、ERMを大幅に上回るアルゴリズムは存在しない、という事が分かった。
まとめ
- ドメイン汎化(Domain Generalization)のアルゴリズムはERMが原則最強
- 条件をそろえてアルゴリズム間の性能を比較するプラットフォームを作った




